
Grok 4: el modelo de IA "más inteligente" de Musk, construido con 200.000 GPUs
北京时间7月10日,经过一小时的全球瞩目等待,马斯克终于揭开


北京时间7月10日,经过一小时的全球瞩目等待,马斯克终于揭开

El equipo híbrido de Tencent ha lanzado Hunyuan3D-PolyGen, el primer gran modelo generativo 3D de la industria que cumple los estándares de grado artístico, capaz de generar modelos 3D profesionales que pueden utilizarse en el desarrollo de juegos y la producción de cine y TV, mejorando significativamente la eficiencia de los artistas. El modelo presenta importantes avances tecnológicos en cuanto a capacidad de modelado de geometrías complejas y estabilidad de generación, admite múltiples métodos de entrada y reduce significativamente el número de fichas y mejora la calidad del modelado mediante estrategias de compresión BPT y optimización del aprendizaje por refuerzo. Actualmente está disponible para experimentar de forma gratuita a través de la plataforma Tencent Hybrid 3D.


El equipo de creación inteligente de Byte Jump lanzó el modelo XVerse, que se basa en la arquitectura DiT y realiza el control independiente y preciso de múltiples sujetos en escenas complejas, incluyendo las dimensiones de gesto, estilo, luz y sombra, e identidad. Su rendimiento en el control de múltiples sujetos, la calidad estética y la similitud de identidad es excelente, y el sistema de pruebas XVerseBench construido muestra que el rendimiento es significativamente mejor que el de los productos de la competencia.XVerse puede soportar la generación dinámica, la edición interactiva y la expansión de escenas complejas en el futuro, y se espera que promueva el desarrollo de aplicaciones de la industria AIGC.

OmniAvatar es un sistema humano digital acústico desarrollado conjuntamente por la Universidad de Zhejiang y Alibaba Group, capaz de generar vídeos naturales y fluidos de cuerpo entero a partir de fotos, audio y texto. En comparación con la tecnología tradicional de "avatar parlante", el sistema logra avances en la coordinación del movimiento corporal, la sincronización de audio/vídeo de alta precisión y el control de texto. El sistema ha sido probado y ha demostrado ser líder en calidad de imagen, fluidez de vídeo y sincronización de la boca, y es actualmente el único modelo que puede generar de forma sincrónica animaciones faciales y de todo el cuerpo. El proyecto es de código abierto y el artículo se ha publicado en arXiv.
MuseSteamer, un modelo de generación multimodal lanzado por el equipo comercial de I+D de Baidu, ha alcanzado el primer puesto mundial en la evaluación de vídeo gráfico de VBench, y ha logrado importantes avances en la generación simultánea de audio y vídeo chinos, el perfeccionamiento del sistema de descripción y el control de estilo, y ha demostrado una capacidad de comprensión semántica superior. A pesar de la falta de capacidad de programación de objetivos y de la lentitud de la velocidad de generación, MuseSteamer sigue siendo un hito importante en el desarrollo de la tecnología de vídeo de IA nacional, y la versión Turbo se ha abierto para experimentar de forma gratuita.

Tencent AI Lab ha lanzado SongGeneration, un modelo de generación musical de código abierto que supera los retos de la calidad del sonido, la musicalidad y la velocidad de generación gracias a una arquitectura técnica y unos métodos de formación innovadores. El modelo soporta cuatro funciones básicas: control inteligente del texto, seguimiento preciso del estilo, generación multipista y clonación tímbrica, lo que reduce significativamente el umbral de creación musical. La estrategia de entrenamiento en tres fases y la alineación multidimensional de las preferencias humanas mejoran aún más el efecto de generación. La evaluación autorizada muestra que el modelo ocupa el primer lugar entre los modelos de código abierto, cerca del nivel de los modelos comerciales, y se ha abierto a la experiencia en Hugging Face y GitHub, ayudando a popularizar la creación inteligente de música.
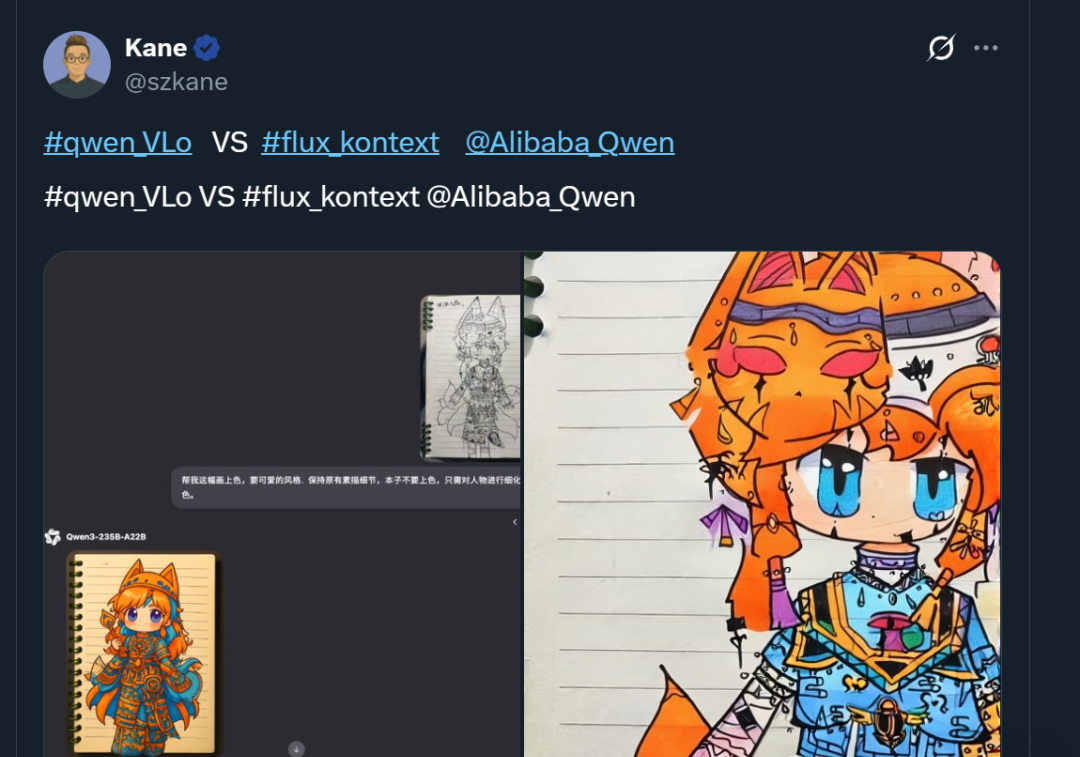
AliCloud acaba de lanzar su último modelo de IA multimodal, Qwen-VLo, cuyas capacidades de generación y edición de imágenes han sido muy bien valoradas por los usuarios, superando incluso a GPT-4o. El modelo cuenta con las ventajas de una captura de detalles mejorada, edición de imágenes con un solo comando, compatibilidad con varios idiomas y adaptación flexible de la resolución, y rinde bien en reconocimiento de imágenes, sustitución de objetos y generación progresiva. Ya está disponible gratuitamente a través de la plataforma Qwen Chat.
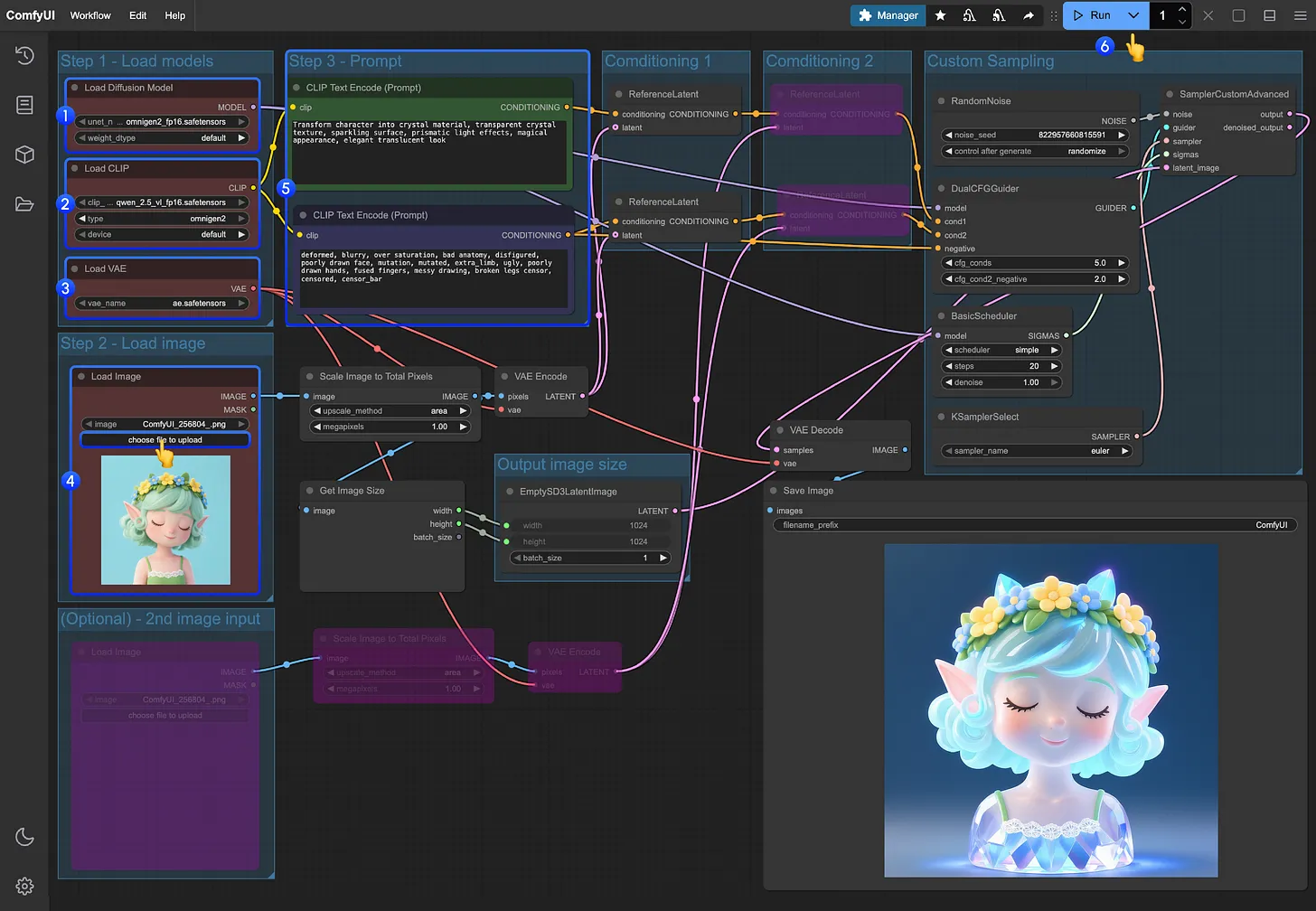

GPT-5 integrará varias herramientas de IA, como Codex y Operator, para integrar funciones de programación, investigación, operación y memoria. Es totalmente multimodal y puede manejar entradas de voz, imagen, código y vídeo, además de alternar de forma inteligente entre los modos de inferencia y diálogo. Según las pruebas realizadas, su eficacia de programación puede multiplicarse por 3, lo que lo sitúa como un avance clave en la tercera fase del desarrollo de la AGI. Se espera que salga a la venta este año, lo que suscitará inquietudes en el sector y debates sobre seguridad.
文章对Manus、扣子空间、Lovart、Flowith Neo、Skywork和超级麦吉六款主流AI Agent产品进行了评测,从执行能力、可信度和使用频次三个维度分析其市场竞争力。Lovart、Skywork和超级麦吉在各自垂直领域表现出色,总评分达18分,而通用型产品面临入口和整合的挑战。文章指出专业化与通用化共存、可交付性、信任机制和入口整合将成为Agent发展的重要方向。

MCP(Model Context Protocol)是一种允许大模型与外部工具和服务交互的协议,Cursor IDE通过MCP Servers功能支持AI助手调用工具执行搜索、浏览网页和代码操作。用户可通过设置界面添加MCP服务器,配置方式包括全局和项目级别。MCP支持多种语言编写,允许AI自动或手动运行工具并返回结果,包括图像。推荐资源包括Awesome-MCP-ZH、AIbase及多个MCP客户端工具。常用MCP服务如Sequential Thinking、Brave Search、Magic MCP等,分别增强AI的思考能力、搜索能力、前端开发效率等功能。
2025年5月,谷歌推出Veo 3,首次实现AI音画同步生成,使AI视频角色能“开口说话”。该模型突破包括4K画面、物理一致性与音效同步等,利用V2A技术编码视频视觉为语义信号,生成匹配音轨,应用于脱口秀、游戏直播、音乐会等场景。虽在复杂动作生成存在不足,但商业化前景显著,定价分层,冲击传统广告与影视制作行业。

Google最新发布的三款Gemma专业化模型——MedGemma、SignGemma和DolphinGemma,代表AI模型从通用性向垂直领域深度适配的重要转变。MedGemma聚焦医疗场景,提供多模态影像和高精度文本推理能力;SignGemma支持多语言手语翻译,帮助听障群体交流;DolphinGemma探索合成海豚语音,推动跨物种沟通研究。这些模型在提升专业性能的同时,兼顾计算效率与部署便利性,为AI产业化落地提供了新路径。

Claude 4 的发布使 AI 对话技术迈上新台阶。要有效使用其能力,需掌握精确、结构化和上下文驱动的提示词工程技巧。提供清晰的指令、充足的背景信息和高质量示例,可以显著提高认知表现和输出质量。同时,结合格式控制、思考引导和并行处理等高级技巧,可进一步优化 AI 交互效率与专业水平。

Lovart是一款专为设计定制的AI智能代理,具备图像生成、视频制作、3D建模等功能,支持智能任务分解与可编辑图层,提升设计效率与灵活性。文章分析其核心优势与技术架构,并提供优化提示词的策略及真实案例,展示其在品牌设计、IP角色创作等方面的应用价值。

Anthropic发布Claude 4系列,涵盖Opus 4和Sonnet 4两个版本,专注编程和高级推理任务。CEO Dario Amodei在开发者大会上宣布该系列全面超越竞品,性能在多个基准测试中领先,同时推出Claude Code及全新API功能,推动AI与开发模式变革。

本文介绍了如何通过实用提示词技巧更高效地与AI助手沟通,包括拆解复杂问题、多感官学习、记忆强化、检验理解等方法,并提供具体示例和语言模板。技巧涉及分步指导、简化解释、故事化呈现和知识测验,适用于不同学习场景,结合灵活应用可大幅提升学习效果和对话质量。
Manus上线图像生成功能,新用户获赠1000积分并每日补充300积分。平台采用深度思考流程,支持多工具协同与任务交互调整。测试案例显示其可完成复杂图像生成、品牌设计、网页部署等任务。积分消耗较高,基础功能免费额度有限,付费订阅分三档。Manus优势在于意图理解与全流程执行,但存在速度慢、质量波动和成本高等问题,未来仍有提升空间。

OpenAI 的 Codex 是一款面向软件工程师的云端编程智能体,可提升开发效率。2025年5月仅对 Pro、Enterprise 和 Team 用户开放,需完成 GitHub 关联与 MFA 认证。Codex 提供 Ask(查询)和 Code(编码)两种模式,支持任务并行处理及 PR 创建。通过合理提示设计与项目配置优化,可在代码审查、Bug 修复、自动化测试等场景中显著提升工作效率。



número público

Cooperación Wechat