
Grok 4: самая "умная" модель искусственного интеллекта Маска, построенная на 200 000 графических процессорах
10 июля по пекинскому времени, после часа ожидания, Маск наконец представил миру


10 июля по пекинскому времени, после часа ожидания, Маск наконец представил миру

Гибридная команда Tencent выпустила Hunyuan3D-PolyGen, первую в отрасли генеративную 3D-модель большого размера, соответствующую стандартам художественного уровня, способную генерировать профессиональные 3D-модели, которые можно использовать в разработке игр, производстве фильмов и телепередач, значительно повышая эффективность работы художников. Модель обладает значительным технологическим прорывом в области моделирования сложной геометрии и стабильности генерации, поддерживает множество методов ввода, значительно сокращает количество маркеров и улучшает качество моделирования благодаря стратегиям оптимизации BPT-сжатия и обучения с усилением. В настоящее время она доступна для бесплатного ознакомления на платформе Tencent Hybrid 3D.

Новая эра дизайна плакатов В современной бурно развивающейся цифровой креативной индустрии дизайн плакатов как

Команда разработчиков интеллектуальных решений Byte Jump выпустила модель XVerse, основанную на архитектуре DiT и реализующую независимое и точное управление несколькими объектами в сложных сценах, включая аспекты жеста, стиля, света и тени, а также идентичности. XVerse обладает превосходными характеристиками в области управления несколькими объектами, эстетического качества и сходства идентичности, а созданная тестовая система XVerseBench показывает, что его производительность значительно выше, чем у конкурирующих продуктов. XVerse может поддерживать динамическое генерирование, интерактивное редактирование и расширение сложных сцен в будущем, и, как ожидается, будет способствовать развитию отраслевых приложений AIGC.

OmniAvatar - это аудиоуправляемая система цифрового человека, совместно разработанная Чжэцзянским университетом и Alibaba Group, способная генерировать естественные и плавные видеоролики движения всего тела на основе фотографий, аудио и текстовых подсказок. По сравнению с традиционной технологией "говорящего аватара", система достигла прорыва в координации движений тела, высокоточной синхронизации аудио/видео и управлении текстом. Система была протестирована и признана лучшей по качеству изображения, плавности видео и синхронизации рта, и на данный момент является единственной моделью, которая может синхронно генерировать анимацию лица и всего тела. Проект получил открытый доступ, а статья опубликована в arXiv.
MuseSteamer, мультимодальная модель генерации, запущенная командой коммерческих исследований и разработок Baidu, заняла первое место в мире по оценке графического видео в VBench и совершила важный прорыв в одновременной генерации китайского аудио и видео, усовершенствовала систему описания и управления стилями, а также продемонстрировала превосходные возможности семантического понимания. Несмотря на отсутствие возможности планирования объектива и низкую скорость генерации, MuseSteamer по-прежнему является важной вехой в развитии отечественных видеотехнологий искусственного интеллекта, а Turbo-версия была открыта для свободного ознакомления.

Tencent AI Lab запустила SongGeneration, модель генерации музыки с открытым исходным кодом, которая решает проблемы качества звука, музыкальности и скорости генерации благодаря инновационной технической архитектуре и методам обучения. Модель поддерживает четыре основные функции: интеллектуальное управление текстом, точное следование стилю, генерацию нескольких треков и клонирование тембра, что значительно снижает порог создания музыки. Трехступенчатая стратегия обучения и многомерное выравнивание предпочтений человека еще больше усиливают эффект генерации. Авторитетная оценка показывает, что модель занимает первое место среди моделей с открытым исходным кодом, близка к уровню коммерческих моделей и открыта для опыта на Hugging Face и GitHub, способствуя популяризации интеллектуального создания музыки.
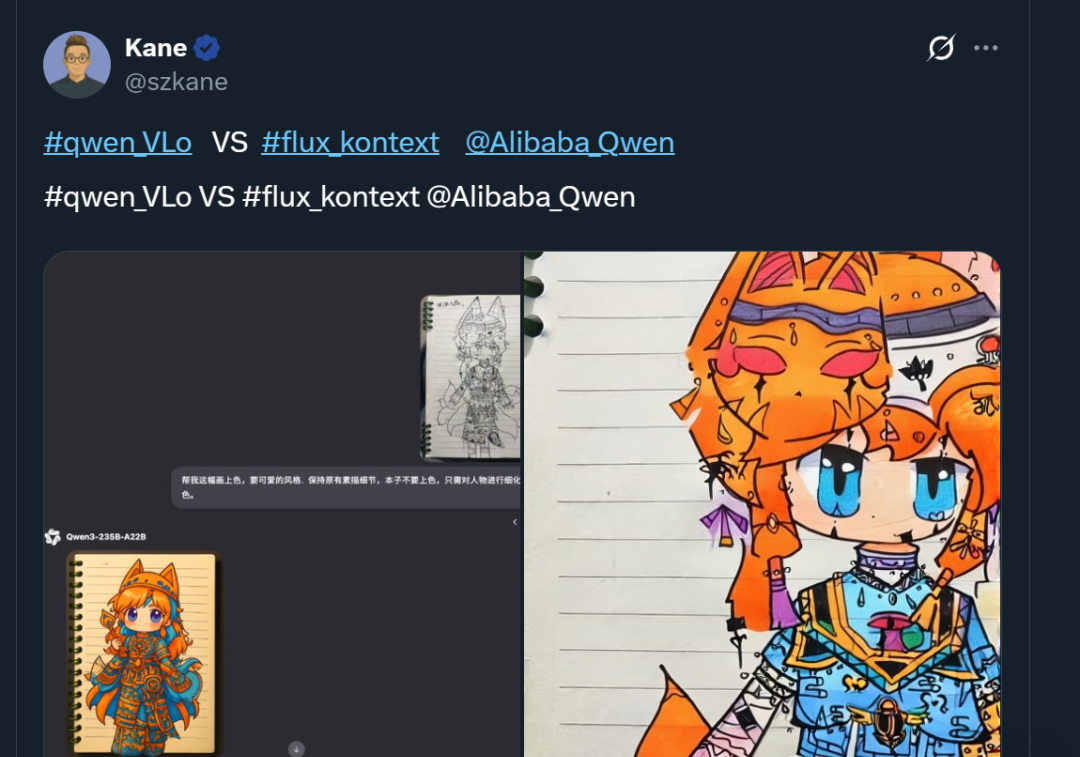
Компания AliCloud недавно выпустила новейшую мультимодальную модель искусственного интеллекта Qwen-VLo, возможности которой по созданию и редактированию изображений были высоко оценены пользователями и даже превзошли GPT-4o. Модель обладает такими преимуществами, как улучшенный захват деталей, редактирование изображений с помощью одной команды, поддержка нескольких языков и гибкая адаптация разрешения, а также отлично справляется с распознаванием изображений, заменой объектов и прогрессивной генерацией. Теперь она доступна бесплатно через платформу Qwen Chat.
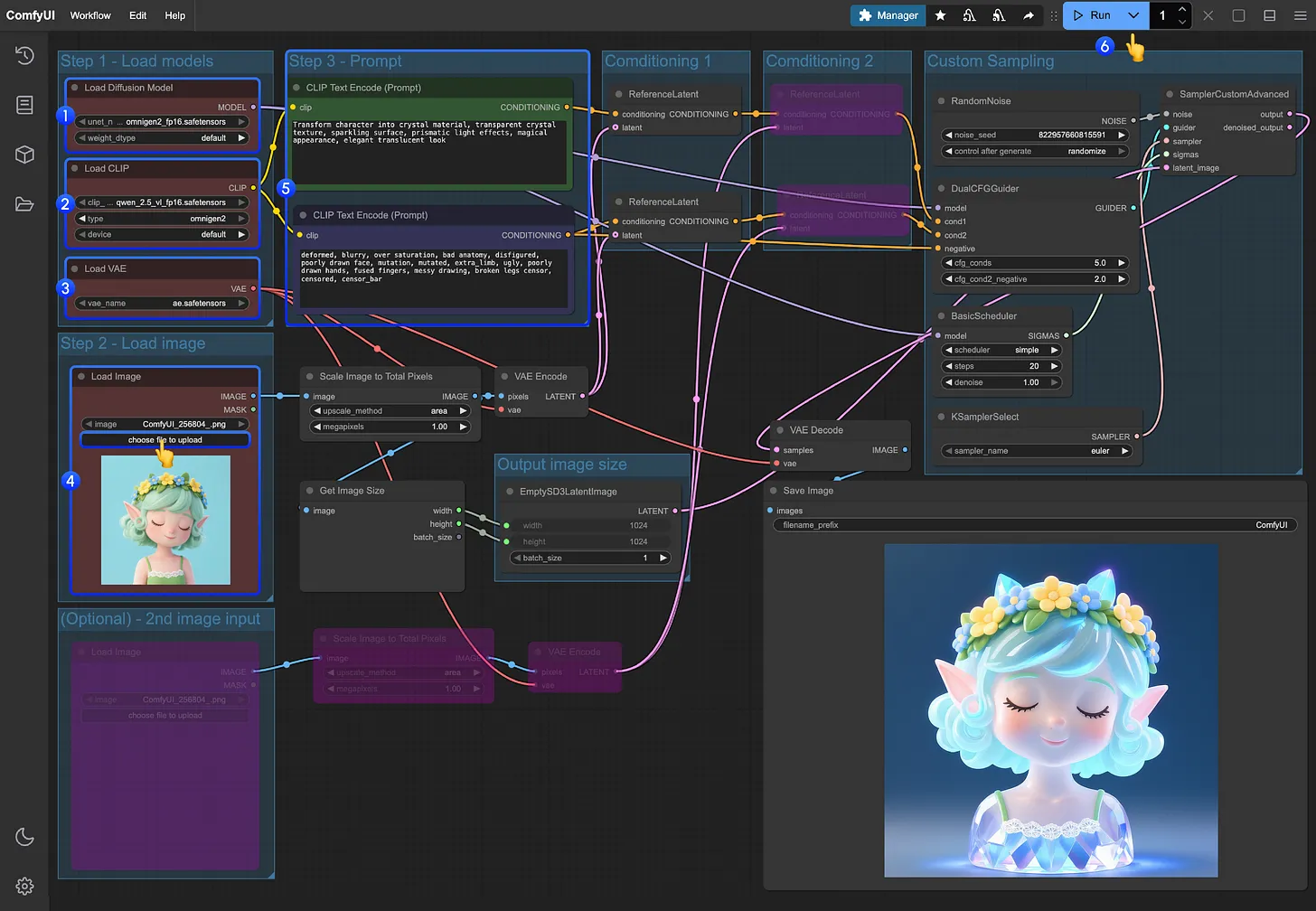
В современном быстро развивающемся мире искусственного интеллекта OmniGen2, новаторский мульти

В GPT-5 будет интегрировано несколько инструментов искусственного интеллекта, таких как Codex и Operator, для интеграции функций программирования, исследования, работы и запоминания. Он полностью мультимодален и может обрабатывать голосовые, графические, кодовые и видеоданные, а также интеллектуально переключаться между режимами умозаключений и диалога. Согласно тестам, эффективность программирования может быть увеличена в 3 раза, что делает его ключевым прорывом на третьем этапе развития AGI. Ожидается, что он будет выпущен в течение этого года, что вызовет беспокойство в отрасли и дискуссии о безопасности.
В статье рассматриваются шесть основных продуктов AI Agent - Manus, Buckle Space, Lovart, Flowith Neo, Skywork и Super Magee - и анализируется их конкурентоспособность на рынке по трем параметрам: способность к исполнению, надежность и частота использования. Lovart, Skywork и Super Magee занимают лидирующие позиции в своих вертикалях с общим баллом 18, в то время как Дженерализеры сталкиваются с проблемами входа и интеграции. В статье отмечается, что сосуществование специализации и генерализации, доставляемость, механизм доверия и интеграция порталов станут важными направлениями развития агентов.

Основные принципы разработки реплик При сотрудничестве с кодовыми помощниками ИИ необходимо использовать эффективные стратегии коммуникации, чтобы
MCP (Model Context Protocol) - это протокол, позволяющий большим моделям взаимодействовать с внешними инструментами и сервисами. Cursor IDE поддерживает ассистентов ИИ для вызова инструментов для выполнения поиска, просмотра веб-страниц и операций с кодом с помощью функции MCP-серверов. Серверы MCP можно добавлять через интерфейс настроек и настраивать как на глобальном, так и на проектном уровне. MCP написан на нескольких языках и позволяет ИИ запускать инструменты автоматически или вручную и возвращать результаты, включая изображения. Рекомендуемые ресурсы включают Awesome-MCP-ZH, AIbase и несколько клиентских инструментов MCP. Часто используемые MCP-сервисы, такие как Sequential Thinking, Brave Search, Magic MCP и т. д., повышают способность ИИ к мышлению, поиску, эффективность фронтенд-разработки и другие возможности, соответственно.
В мае 2025 года Google запустила Veo 3, впервые обеспечив синхронное генерирование аудио и видео ИИ, благодаря чему видеоперсонажи ИИ могут "говорить". Прорывная модель включает в себя 4K-картинку, физическую согласованность, синхронизацию звука и т. д., использование технологии V2A для кодирования видеоизображений в виде семантических сигналов, генерирование соответствующих аудиодорожек и применение в ток-шоу, живых играх, концертах и других сценах. Несмотря на недостатки в создании сложных действий, перспективы коммерциализации значительны, а многоуровневое ценообразование окажет влияние на традиционные отрасли рекламы и кинопроизводства.

Три недавно выпущенные компанией Google специализированные модели Gemma - MedGemma, SignGemma и DolphinGemma - представляют собой важный сдвиг в моделях ИИ от обобщения к глубокой вертикальной адаптации домена. MedGemma фокусируется на медицинских сценариях, предоставляя мультимодальные изображения и высокоточные текстовые рассуждения. SignGemma поддерживает многоязычный сурдоперевод, помогая общаться группам людей с нарушениями слуха, а DolphinGemma занимается синтезом речи дельфинов для исследования межвидовой коммуникации. Эти модели повышают профессиональную производительность, учитывая при этом эффективность вычислений и удобство развертывания, обеспечивая новый путь для индустриализации ИИ.

Выпуск Claude 4 выводит технологию диалогов ИИ на новый уровень. Эффективное использование ее возможностей требует точных, структурированных и контекстно-ориентированных навыков разработки слов-подсказок. Предоставление четких инструкций, достаточной контекстной информации и высококачественных примеров может значительно улучшить когнитивные показатели и качество вывода. В то же время сочетание таких передовых технологий, как управление форматом, мыслительная деятельность и параллельная обработка, позволяет еще больше оптимизировать эффективность и профессионализм взаимодействия ИИ.

Lovart - это интеллектуальный агент ИИ, предназначенный для дизайна, с такими функциями, как генерация изображений, создание видео, 3D-моделирование и т. д. Он поддерживает интеллектуальную декомпозицию задач и редактируемые слои для повышения эффективности и гибкости дизайна. В статье анализируются его основные преимущества и техническая архитектура, а также приводятся стратегии и реальные примеры оптимизации слов реплики, демонстрирующие ценность его применения в дизайне брендов, создании персонажей ИС и других аспектах.

Компания Anthropic запускает серию Claude 4, включающую версии Opus 4 и Sonnet 4, ориентированную на программирование и решение сложных задач. На конференции разработчиков генеральный директор Дарио Амодеи объявил, что эта серия превосходит конкурентов по всем параметрам, лидируя по производительности в различных бенчмарках, а также о запуске Claude Code и новых функций API, которые приведут к смене парадигмы в работе над ИИ и разработкой. смена парадигмы.

В этой статье рассказывается о том, как повысить эффективность общения с ИИ-помощниками с помощью практических техник подсказок, включая методы разбора сложных задач, мультисенсорного обучения, усиления памяти и проверки понимания, а также приводятся конкретные примеры и языковые шаблоны. Советы включают в себя пошаговые инструкции, упрощенные объяснения, сюжетные презентации и викторины на знание, которые применимы к различным сценариям обучения, а сочетание гибкого применения может значительно улучшить эффект обучения и качество диалога.
Manus начинает работать с генерацией изображений, новые пользователи получают 1000 бонусных баллов и 300 ежедневных пополнений. Платформа использует процесс глубокого мышления, поддерживающий совместную работу нескольких инструментов и настройку взаимодействия задач. Тестовые примеры показывают, что она может выполнять сложную генерацию изображений, дизайн бренда, развертывание веб-сайтов и другие задачи. Расход баллов высок, бесплатный объем базовых функций ограничен, а платная подписка разделена на три уровня. Преимущества Manus заключаются в понимании намерений и исполнении всего процесса, но есть проблемы медленной скорости, колебаний качества и высокой стоимости, так что в будущем есть куда совершенствоваться.

Codex от OpenAI - это облачный интеллект программирования для инженеров-программистов, повышающий эффективность разработки. Доступен с мая 2025 года только для пользователей Pro, Enterprise и Team, имеющих принадлежность к GitHub и сертификацию MFA. Codex предлагает режимы Ask и Code, поддерживает параллельную обработку задач и создание PR. Codex предлагает режимы Ask и Code, поддерживает параллельную обработку заданий и создание PR. Благодаря продуманному дизайну и оптимизации конфигурации проекта, он может значительно повысить эффективность работы при рецензировании кода, исправлении ошибок, автоматизированном тестировании и других сценариях.



публичный номер

Сотрудничество Wechat