
Grok 4: Musk's "Smartest" AI Model Built on 200,000 GPUs
On July 10, Beijing time, after an hour of waiting for the world's attention, Musk finally unveiled the


On July 10, Beijing time, after an hour of waiting for the world's attention, Musk finally unveiled the

Tencent's hybrid team has launched Hunyuan3D-PolyGen, the industry's first 3D generative large model that meets the standards of art grade, capable of generating professional 3D models that can be used in game development and film and TV production, significantly improving the efficiency of artists. The model has significant technological breakthroughs in complex geometry modeling capability and generation stability, supports multiple input methods, and significantly reduces the number of tokens and improves modeling quality through BPT compression technology and reinforcement learning optimization strategy. It can be experienced for free through the Tencent Hybrid 3D platform.

The New Era of Poster Design In today's booming digital creative industry, poster design as a

The Byte Jump intelligent creation team launched the XVerse model, which is based on the DiT architecture and realizes the independent and precise control of multiple subjects in complex scenes, including the dimensions of gesture, style, light and shadow, and identity. Its performance in multi-subject control, aesthetic quality and identity similarity is excellent, and the XVerseBench test system constructed shows that the performance is significantly better than that of competing products.XVerse may support dynamic generation, interactive editing and complex scene expansion in the future, and is expected to promote the development of AIGC industrial applications.

OmniAvatar is an audio-driven digital human system jointly developed by Zhejiang University and Alibaba Group, capable of generating natural and smooth full-body motion video based on static photos, audio and text prompts. Compared with the traditional "talking avatar" technology, the system achieves breakthroughs in body movement coordination, high-precision audio and video synchronization, and text control. After testing, it is the only model that can synchronize facial and full-body animation, and is ahead in image quality, video smoothness and mouth synchronization. The project has been open-sourced and the paper is published in arXiv.
MuseSteamer, a multimodal generation model launched by Baidu's commercial R&D team, has achieved the world's first place in VBench's graphic video evaluation, and has made important breakthroughs in the simultaneous generation of Chinese audio and video, refined description system and style control, and has demonstrated superior semantic comprehension capabilities. Despite the lack of lens scheduling ability and slow generation speed, MuseSteamer is still an important milestone in the development of domestic AI video technology, and the Turbo version has been opened for free to experience.

Tencent AI Lab has launched SongGeneration, an open source music generation model, which breaks through the challenges of sound quality, musicality and generation speed through innovative technical architecture and training methods. The model supports four core functions: intelligent text control, precise style following, multi-track generation and timbre cloning, significantly lowering the threshold of music creation. The three-stage training strategy and multi-dimensional human preference alignment further enhance the generation effect. Authoritative evaluation shows that the model ranks first among open source models, close to the level of commercial models, and has been open to experience in Hugging Face and GitHub, helping the popularization of intelligent music creation.
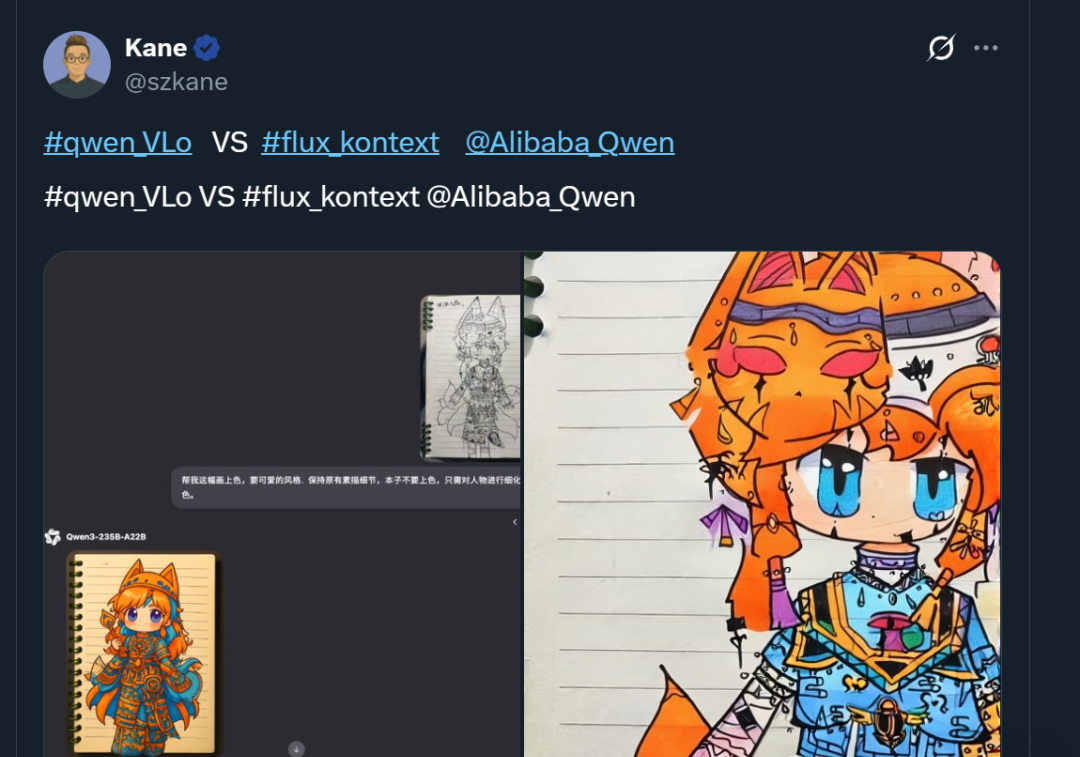
AliCloud recently released its latest multimodal AI model, Qwen-VLo, whose image generation and editing capabilities have been highly rated by users, even surpassing GPT-4o. The model has the advantages of enhanced detail capture, single-command image editing, multi-language support, and flexible resolution adaptation, and excels in image recognition, object replacement, and progressive generation. It is now available for free via the Qwen Chat platform.
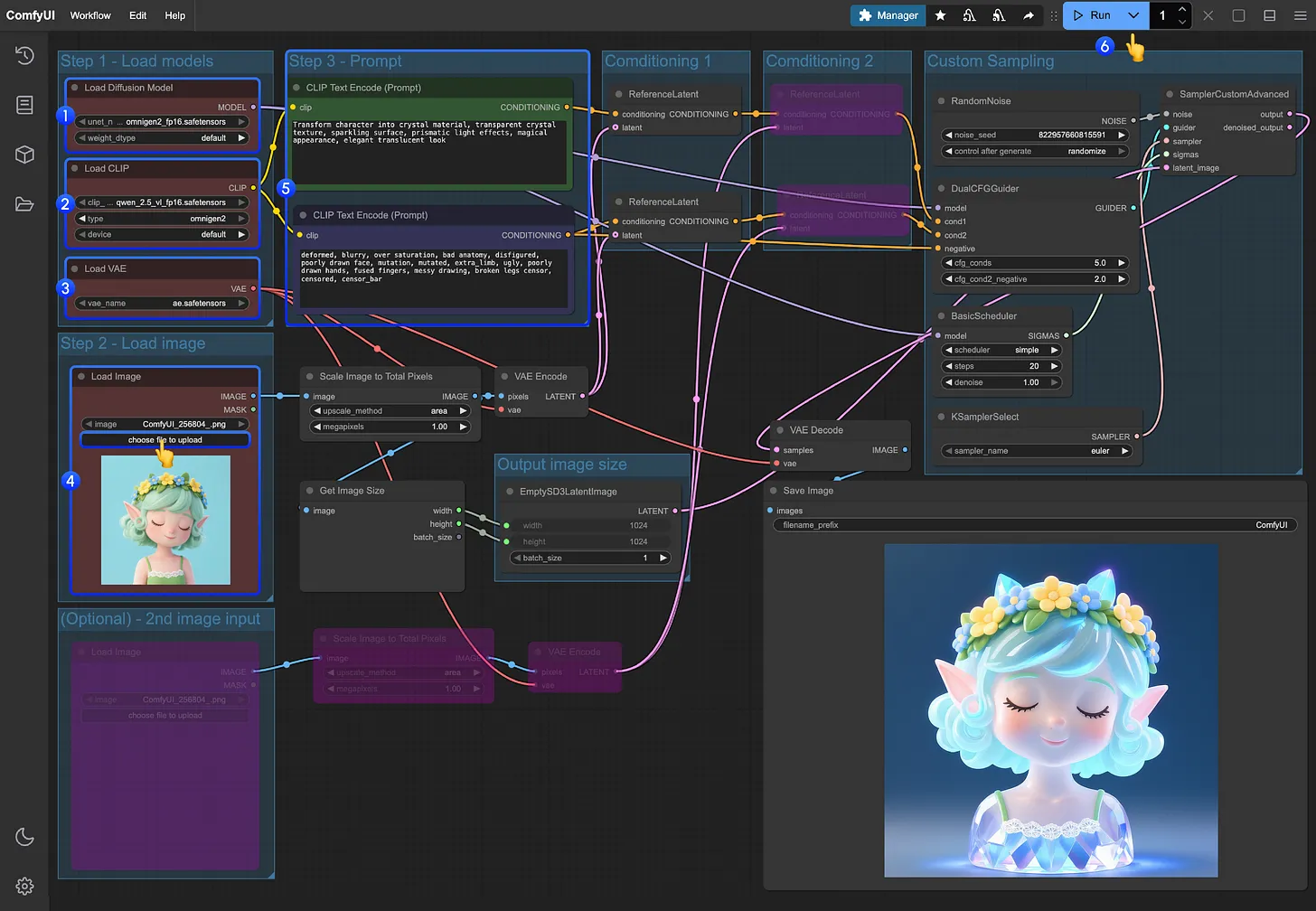
In today's rapidly evolving world of artificial intelligence, OmniGen2, a groundbreaking multi-

GPT-5 will integrate several AI tools such as Codex and Operator to realize the integration of programming, research, operation and memory functions. It is fully multimodal and can handle voice, image, code and video inputs, and can intelligently switch between inference and dialog modes. According to tests, its programming efficiency can be increased by 3 times, positioning it as a key breakthrough in the third phase of AGI development. It is expected to be released within this year, triggering industry concerns and security discussions.
The article reviews six mainstream AI Agent products, Manus, Buckle Space, Lovart, Flowith Neo, Skywork, and Super Magee, and analyzes their market competitiveness in terms of execution capability, trustworthiness, and frequency of use.Lovart, Skywork, and Super Magee excel in their respective verticals, with a total score of 18, while the Generalizers face entry and integration challenges. The article points out that the coexistence of specialization and generalization, deliverability, trust mechanism and entrance integration will become important directions for Agent development.

Core Principles of Cue Engineering When collaborating with AI code assistants, effective communication strategies to
MCP (Model Context Protocol) is a protocol that allows large models to interact with external tools and services. Cursor IDE supports AI assistants to invoke tools to perform searches, browse the web, and code operations through the MCP Servers feature. MCP servers can be added through the Settings interface and configured at both the global and project levels.MCP is written in multiple languages and allows the AI to run tools automatically or manually and return results, including images. Recommended resources include Awesome-MCP-ZH, AIbase, and several MCP client tools. Commonly used MCP services such as Sequential Thinking, Brave Search, Magic MCP, etc. enhance AI's ability to think, search, front-end development efficiency, and other features, respectively.
In May 2025, Google launched Veo 3, the first to achieve AI audio and video synchronization generation, so that AI video characters can "speak". The model breakthroughs include 4K picture, physical consistency and sound synchronization, etc., using V2A technology to encode video vision into semantic signals, generating matching audio tracks, which are applied to talk shows, live games, concerts and other scenes. Although there are deficiencies in complex action generation, the commercialization prospects are significant, pricing tiering, impact on traditional advertising and film production industry.

Google's three newly released Gemma specialization models - MedGemma, SignGemma, and DolphinGemma - represent an important shift in AI models from generality to deep vertical domain adaptation.MedGemma focuses on medical scenarios, providing multimodal image and high-precision text reasoning capabilities; SignGemma supports multilingual sign language translation to help hearing-impaired groups communicate; DolphinGemma explores synthesizing dolphin speech to promote cross-species communication research. These models provide a new path for the industrialization of AI while improving professional performance and taking into account computational efficiency and ease of deployment.

The release of Claude 4 takes AI dialog technology to the next level. Effective use of its capabilities requires precise, structured and context-driven cue word engineering skills. Providing clear instructions, sufficient contextual information, and high-quality examples can significantly improve cognitive performance and output quality. At the same time, combining advanced techniques such as format control, thought leadership, and parallel processing can further optimize the efficiency and professionalism of AI interactions.

Lovart is an AI intelligent agent customized for design with image generation, video production, 3D modeling, etc. It supports intelligent task decomposition and editable layers to enhance design efficiency and flexibility. The article analyzes its core advantages and technical architecture, and provides strategies for optimizing cue words and real cases to demonstrate its application value in brand design, IP character creation and other aspects.

Anthropic launches the Claude 4 series, spanning Opus 4 and Sonnet 4 versions, focused on programming and advanced reasoning tasks. at the developer conference, CEO Dario Amodei announced that the series outperforms the competition across the board, leading the way in performance across multiple benchmarks, as well as launching Claude Code and new API features that will drive a paradigm shift in the way AI and development are done. model change.

This article introduces how to communicate with AI assistants more efficiently through practical cue word techniques, including methods of disassembling complex problems, multi-sensory learning, memory reinforcement, and testing comprehension, and provides specific examples and language templates. The tips involve step-by-step instructions, simplified explanations, storytelling presentations and knowledge quizzes, which are applicable to different learning scenarios, and the combination of flexible application can significantly improve the learning effect and the quality of conversations.
Manus goes live with image generation, new users get 1,000 bonus points and 300 daily refills. The platform adopts a deep thinking process and supports multi-tool collaboration and task interaction adjustment. Test cases show that it can accomplish complex image generation, brand design, web deployment and other tasks. The consumption of points is high, the free amount of basic functions is limited, and the paid subscription is divided into three levels. Manus' strengths lie in the understanding of intentions and the execution of the whole process, but there are problems such as slow speed, fluctuating quality and high cost, and there is still room for improvement in the future.

OpenAI's Codex is a cloud-based programming intelligence for software engineers that improves development efficiency. available May 2025 for Pro, Enterprise, and Team users only, with GitHub affiliation and MFA certification. codex offers both Ask and Code modes, and supports parallel processing and PR creation for tasks. Codex provides both Ask and Code modes, supporting parallel processing of tasks and PR creation. It can significantly improve work efficiency in code review, bug fixing, automated testing and other scenarios through reasonable prompt design and project configuration optimization.



public number

Cooperation