



Hunyuan3D-PolyGen:テンセント、アートレベル3D生成の新たなブレークスルーを発表
テンセントのハイブリッドチームは、業界初のアートグレードの基準を満たした3Dジェネレーティブ・ラージモデル「Hunyuan3D-PolyGen」を発表した。このモデルは、ゲーム開発や映画・テレビ制作で使用できるプロフェッショナルな3Dモデルを生成でき、アーティストの作業効率を大幅に向上させる。このモデルは、複雑形状のモデリング能力と生成の安定性において大きな技術的ブレークスルーを持ち、複数の入力メソッドをサポートし、BPT圧縮と強化学習最適化戦略によってトークン数を大幅に削減し、モデリング品質を向上させます。現在、Tencent Hybrid 3Dプラットフォームを通じて無料で体験することができる。

ポスタークラフト:AIを活用したポスターデザインの画期的なブレークスルー
ポスターデザインの新時代 活況を呈する今日のデジタル・クリエイティブ業界において、ポスターデザインは、「ポスターデザイン」としての地位を確立している。

バイトジャンプXVerse:画期的なマルチ被写体画像生成技術を徹底分析
Byte Jumpのインテリジェントクリエーションチームは、DiTアーキテクチャをベースとし、ジェスチャー、スタイル、光と影、アイデンティティの次元を含む複雑なシーンにおける複数の被写体の独立かつ正確な制御を実現するXVerseモデルを発表した。XVerseは、DiTアーキテクチャをベースとし、ジェスチャー、スタイル、光と影、アイデンティティの次元を含む複雑なシーンにおける複数の被写体の独立した正確な制御を実現する。その複数被写体の制御、美的品質、アイデンティティの類似性における性能は優れており、構築されたXVerseBenchテストシステムは、その性能が競合製品よりも大幅に優れていることを示している。

OmniAvatar:静止画に生命を吹き込むAIデジタル・ヒューマン・テクノロジーの躍進
OmniAvatarは、浙江大学とアリババ・グループが共同開発した音声駆動型デジタル・ヒューマン・システムで、静止画、音声、テキスト・プロンプトに基づいて、自然で滑らかな全身動作動画を生成することができる。従来の "おしゃべりアバター "技術と比較すると、このシステムは体の動きの調整、高精度の音声と映像の同期、テキスト制御において画期的な進歩を遂げている。このシステムはテストされ、画質、映像の滑らかさ、口の同期においてトップクラスであることが判明しており、現在、顔と全身のアニメーションを同期して生成できる唯一のモデルである。このプロジェクトはオープンソース化されており、論文はarXivに掲載されている。
百度MuseSteamer徹底分析:国内AI動画生成の新たなマイルストーン
バイドゥの商業研究開発チームが発表したマルチモーダル生成モデル「MuseSteamer」は、VBenchのグラフィック動画評価で世界1位を獲得し、中国語の音声と動画の同時生成、洗練された描写システムとスタイル制御において重要なブレークスルーを果たし、優れた意味理解能力を発揮している。MuseSteamerは、レンズのスケジューリング能力がなく、生成速度が遅いという欠点があるものの、国内AI動画技術の発展における重要なマイルストーンであり、ターボ版は無料で体験できるように開放されている。

SongGeneration:AI音楽制作の新時代を切り開くオープンソースツール
Tencent AI Labは、革新的な技術アーキテクチャとトレーニング方法によって、音質、音楽性、生成速度の課題を克服したオープンソースの音楽生成モデル「SongGeneration」を発表した。このモデルは、インテリジェントなテキストコントロール、正確なスタイルフォロー、マルチトラック生成、音色のクローニングという4つのコア機能をサポートしており、音楽制作の敷居を大幅に下げている。3段階のトレーニング戦略と多次元的な人間の嗜好アライメントが、生成効果をさらに高めます。権威ある評価では、このモデルはオープンソースモデルの中で1位であり、商用モデルのレベルに近く、Hugging FaceやGitHubで経験を公開し、音楽創作のインテリジェンスの普及に貢献している。
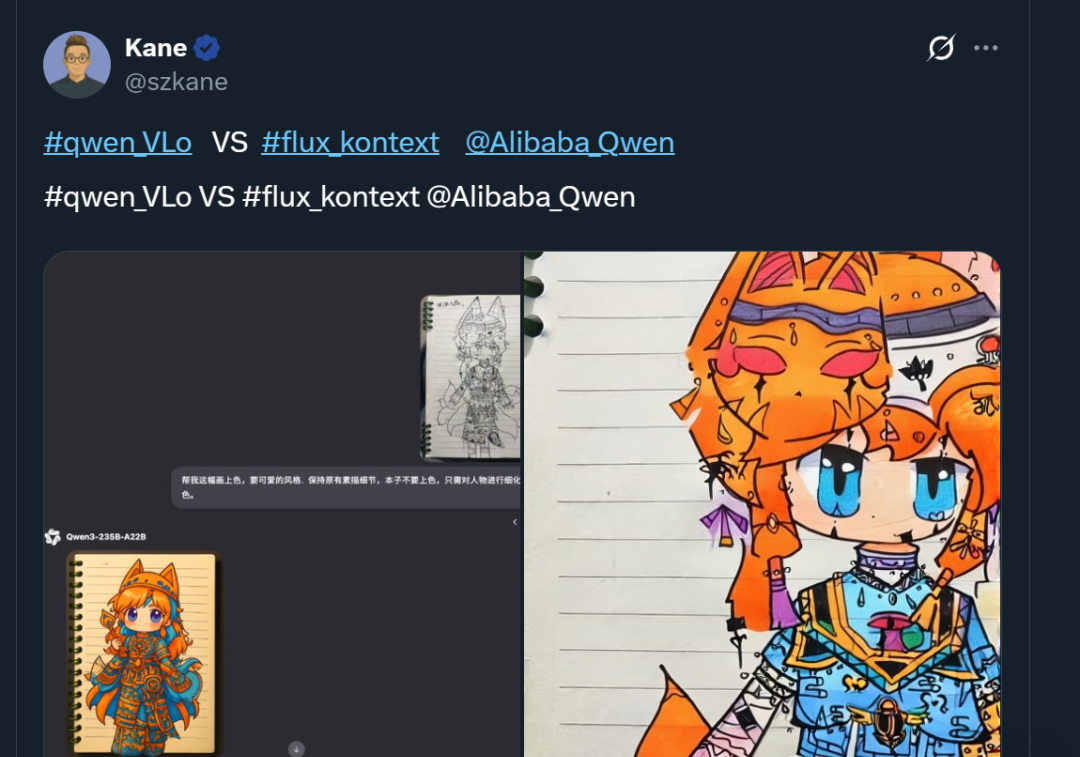
Qwen-VLo:AliCloudのマルチモーダルAIのメジャーリリース
AliCloudはこのほど、最新のマルチモーダルAIモデル「Qwen-VLo」をリリースした。このモデルの画像生成・編集能力は、GPT-4oを凌ぐとユーザーから高い評価を得ている。 このモデルは、強化されたディテールキャプチャ、シングルコマンドでの画像編集、多言語サポート、柔軟な解像度適応などの利点を持ち、画像認識、オブジェクト置換、プログレッシブ生成で優れた性能を発揮する。現在、Qwen Chatプラットフォームを通じて無料でご利用いただけます。

GPT-5登場!OpenAIの次世代スーパーモデルを徹底分析!
GPT-5はCodexやOperatorなど複数のAIツールを統合し、プログラミング、研究、操作、記憶機能を統合する。完全にマルチモーダルであり、音声、画像、コード、ビデオ入力を扱うことができ、推論モードと対話モードをインテリジェントに切り替えることができる。テストによると、プログラミング効率は3倍に向上し、AGI開発の第3段階における重要なブレークスルーと位置づけられる。今年中にリリースされる見込みで、業界の懸念とセキュリティの議論を引き起こしている。
主力AIエージェント6社を徹底検証:商品価値と開発の方向性を探る
この記事では、Manus、Buckle Space、Lovart、Flowith Neo、Skywork、Super Mageeの6つの主流AIエージェント製品をレビューし、実行能力、信頼性、利用頻度の3つの側面から市場競争力を分析している。Lovart、Skywork、Super Mageeは、それぞれの垂直分野で優れており、合計スコアは18である。この記事は、専門化と一般化の共存、配達可能性、信頼メカニズム、ポータル統合が、エージェントの発展にとって重要な方向性になると指摘している。

プログラマーのためのヒント エンジニアリング実践マニュアル
キュー・エンジニアリングの基本原則 AIコード・アシスタントとの共同作業では、効果的なコミュニケーション戦略が必要である。
Cursor MCP サーバー構成ガイドおよび Cursor 実践的 MCP 推奨事項
MCP(Model Context Protocol)は、大規模なモデルが外部のツールやサービスとやり取りできるようにするプロトコルです。 Cursor IDEは、MCPサーバー機能を通じて、AIアシスタントがツールを呼び出して検索を実行したり、ウェブをブラウズしたり、操作をコーディングしたりすることをサポートしています。MCPサーバーは設定インターフェイスから追加でき、グローバルとプロジェクトの両方のレベルで設定できます。MCPは複数の言語で書かれており、AIが自動または手動でツールを実行し、画像を含む結果を返すことができます。推奨リソースには、Awesome-MCP-ZH、AIbase、いくつかのMCPクライアントツールが含まれます。シーケンシャルシンキング、ブレイブサーチ、マジックMCPなど、よく使われるMCPサービスは、それぞれAIの思考能力、検索能力、フロントエンドの開発効率などを向上させる。
Veo 3徹底分析:グーグルのAIビデオ生成における画期的なブレークスルー
2025年5月、グーグルはVeo 3を発表し、AI音声と映像の同期生成を初めて実現し、AI映像キャラクターが「話す」ことができるようになった。モデルのブレークスルーには、4K画像、物理的整合性、音声同期などが含まれ、V2A技術を使って映像ビジュアルを意味信号として符号化し、一致する音声トラックを生成し、トークショー、ゲーム実況、コンサートなどのシーンに適用する。複雑なアクションの生成には欠陥があるが、商業化の見込みは大きく、段階的な価格設定により、従来の広告業界や映画制作業界に影響を与える。

ジェンマのモデルバリエーションを徹底分析:垂直領域AIの技術的ブレークスルーと実用的アプリケーション
MedGemma、SignGemma、DolphinGemmaの3つのGemma専門モデルは、AIモデルの一般性から深い垂直ドメイン適応への重要なシフトを表しています。MedGemmaは医療シナリオに焦点を当て、マルチモーダル画像と高精度のテキスト推論機能を提供する。SignGemmaは聴覚障害者グループのコミュニケーションを支援するために多言語の手話翻訳をサポートし、DolphinGemmaは種を超えたコミュニケーション研究を促進するためにイルカの音声の合成を探求する。これらのモデルは、計算効率と配備の利便性を考慮しながらプロのパフォーマンスを向上させ、AI産業化の新たな道を提供する。

Claude 4 提示词工程完全指南:释放AI助手的真正潜力 🚀
クロード4のリリースは、AI対話技術を次のレベルに引き上げる。その機能を効果的に使用するには、正確で構造化された、文脈に沿ったキューワードエンジニアリングのスキルが必要です。明確な指示、十分な文脈情報、高品質の例を提供することで、認知パフォーマンスと出力品質を大幅に向上させることができます。同時に、フォーマット制御、思考リーダーシップ、並列処理などの高度な技術を組み合わせることで、AI対話の効率性と専門性をさらに最適化することができます。

ロバート・デザイン・エージェント完全解説:初心者から熟練者までのプロンプト・ワード実践ガイド
Lovartはデザインに特化したAIインテリジェントエージェントで、画像生成、ビデオ制作、3Dモデリングなどの機能を持つ。インテリジェントなタスク分解と編集可能なレイヤーをサポートし、デザインの効率と柔軟性を高める。本稿では、Lovartの核となる利点と技術アーキテクチャを分析し、キューワードを最適化するための戦略と実例を提供することで、ブランドデザイン、IPキャラクター作成などにおける応用価値を実証する。

クロード4:AIプログラミング・アシスタントの再定義が始まる
Anthropicは、プログラミングと高度な推論タスクに特化した、Opus 4とSonnet 4のバージョンにまたがるClaude 4シリーズを発表。開発者会議において、CEOのDario Amodeiは、このシリーズが複数のベンチマークにおいてパフォーマンスをリードし、全面的に他社を凌駕していること、またClaude Codeの発表と、AIと開発のあり方にパラダイムシフトをもたらす新しいAPI機能を発表した。パラダイムシフト

AIプロンプトの技術:人工知能にあなたの "人間語 "を理解させる
本稿では、複雑な問題を分解する方法、多感覚学習、記憶強化、理解度テストの方法など、実践的なキューワードテクニックを通じて、AIアシスタントとのコミュニケーションを効率化する方法を紹介し、具体例と言語テンプレートを提供する。ヒントには、段階的な説明、簡略化された説明、ストーリー仕立てのプレゼンテーション、知識クイズなどが含まれ、さまざまな学習シナリオに適用でき、柔軟な応用の組み合わせにより、学習効果と対話の質を大幅に向上させることができる。
マヌスの新機能全貌が明らかに:AIグラフ生成機能が正式稼動
Manusが画像生成で本番稼動、新規ユーザーは1000ボーナスポイント、毎日300リフィル。このプラットフォームは、マルチツールコラボレーションとタスクインタラクションチューニングをサポートするディープシンキングプロセスを採用している。テストケースでは、複雑な画像生成、ブランドデザイン、ウェブ展開、その他のタスクを完了できることが示されている。Manusの長所は意図の把握とプロセス全体の実行にあるが、スピードの遅さ、品質の変動、コストの高さなどの問題があり、今後も改善の余地がある。

Codexアドバンス・ユーザー・ガイド:AIをあなたのプログラミング・パートナーに
OpenAIのCodexは、開発効率を向上させるソフトウェアエンジニアのためのクラウドベースのプログラミングインテリジェンスです。Codexは、AskモードとCodeモードの両方を提供し、タスクの並列処理とPR作成をサポートします。CodexはAskとCodeの両方のモードを提供し、タスクとPR作成の並列処理をサポートします。合理的なプロンプト設計とプロジェクト構成の最適化により、コードレビュー、バグ修正、自動テスト、その他のシナリオにおける作業効率を大幅に向上させることができます。



